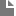def get_page(url):
try:
import urllib2
return urllib2.urlopen(page).read()
except:
return ""
def union(a,b):
for e in b:
if e not in a:
a.append(e)
return a
def get_next_target(page):
start_link=page.find('<a href=')
start_quote=page.find('"',start_link)
end_quote=page.find('"',start_quote+1)
url=page[start_quote+1:end_quote]
return url, end_quote
def get_all_links(page):
links=[]
while True:
url,endpos=get_next_target(page)
if url:
links.append(url)
page=page[endpos:]
else:
break
return links
def add_to_index(index, keyword, url):
if keyword in index:
index[keyword].append(url)
else:
index[keyword]=[url]
def add_page_to_index(index, url, content):
words=content.split()
for word in words:
add_to_index(index, word, url)
def compute_ranks(graph):
d=0.8
numloops=10
ranks={}
npages=len(graph)
for page in graph:
ranks[page]=1.0/npages
for i in range(0,numloops):
newranks={}
for page in graph:
newrank=(1-d)/npages
for node in graph:
if page in graph[node]:
newrank=newrank+d*(ranks[node]/len(graph[node]))
newranks[page]=newrank
ranks=newranks
return ranks
def crawl_web(seed):
tocrawl=[seed]
crawled=[]
index={}
graph={}
while tocrawl:
page=tocrawl.pop()
if page not in crawled:
content=get_page(page)
add_page_to_index(index,page,content)
outlinks=get_all_links(content)
graph[page]=outlinks
union(tocrawl, outlinks)
crawled.append(page)
return index, graph
index, graph = crawl_web('http://udacity.com/cs101x/urank/index.html')
ranks = compute_ranks(graph)
print ranks
Yukarıda gördüğünüz kodla böyle bir sonuç elde etmem gerekirken:
{'http://udacity.com/cs101x/urank/kathleen.html': 0.11661866666666663,
'http://udacity.com/cs101x/urank/zinc.html': 0.038666666666666655,
'http://udacity.com/cs101x/urank/hummus.html': 0.038666666666666655,
'http://udacity.com/cs101x/urank/arsenic.html': 0.054133333333333325,
'http://udacity.com/cs101x/urank/index.html': 0.033333333333333326,
'http://udacity.com/cs101x/urank/nickel.html': 0.09743999999999997}
böyle bir sonuç elde ettiğim için çıldırmama sebep olan bu kodda ne yanlış söyleyebilirseniz çok iyi olur:
{'http://udacity.com/cs101x/urank/kathleen.html': 0.08746399999999999, 'http://udacity.com/cs101x/urank/zinc.html': 0.028999999999999995, 'http://udacity.com/cs101x/urank/hummus.html': 0.028999999999999995, 'http://udacity.com/cs101x/urank/arsenic.html': 0.04059999999999999, '<html>\n<body>\n<h1>\nHummus Recipe\n</h1>\n<p>\n<ol>\n<li> Go to the store and buy a container of hummus.\n<li> Open it.\n</ol>\n</body>\n</html>': 0.04819999999999999, 'http://udacity.com/cs101x/urank/index.html': 0.024999999999999994, "<html>\n<body>\n<h1>\nKathleen's Hummus Recipe\n</h1>\n<p>\n<ol>\n<li> Open a can of garbonzo beans.\n<li> Crush them in a blender.\n<li> Add 3 tablesppons of tahini sauce.\n<li> Squeeze in one lemon.\n<li> Add salt, pepper, and buttercream frosting to taste.\n</ol>\n</body>\n</html>": 0.09497119999999999, 'http://udacity.com/cs101x/urank/nickel.html': 0.07307999999999999}
Kodların amacını özet geçmek gerekirse crawl_web(url_adresi) fonksiyonunu çağırdığımda girdiğim url adresindeki linkleri alıp graph isimli dictionary'e {url_adresi:[linkler]}şeklinde eklemesi gerekiyor.Bir de index kısmı var ama orası sorunla alakalı değil.compute_ranks(graph) fonksiyonunun ise tanımlanan hesapları yapıp 2.bloktaki kodları çevirmesi gerekiyor.Ama gelin görün ki ben yapınca 3.bloktaki saçmalığı çeviriyor.